
Introduction:
In a previous blog post, we discussed some recent success Theta has achieved with our prototype AI model named ‘Naissance’ which is trained to detect the T-72 Main Battle Tank within drone imagery:
‘Naissance’, coming from the Latin verb nasci as in the word ‘nascent’, represents an idea which has recently come into existence. This model was an important first step for to test the viability of machine learning and AI for Aided Target Recognition (ATR) of high value objects within digital imagery. The experiment showed that a high degree of accuracy and specificity could be achieved given the right model architecture and a large enough dataset.
Through a revolution in Neural Network architecture, our firm has developed a next-generation model named ‘Renaissance’ which greatly exceeds the performance of those which came before it. The full process for its development following the older ‘Naissance’ model is described below.
Theta publishes software called OpenAthena™ which allows instant calculation of ground coordinates from any pixel of any single drone image. The user may simply tap anywhere within a drone image to obtain the corresponding ground location. The location can then instantly be shared over a network to devices running ATAK.
The software introduces a novel terrain-raycast technique for processing of remote sensing data from drones. This unique approach has significant advantages in speed and simplicity for processing drone imagery, removing the need for multiple images and intensive post-processing computation.
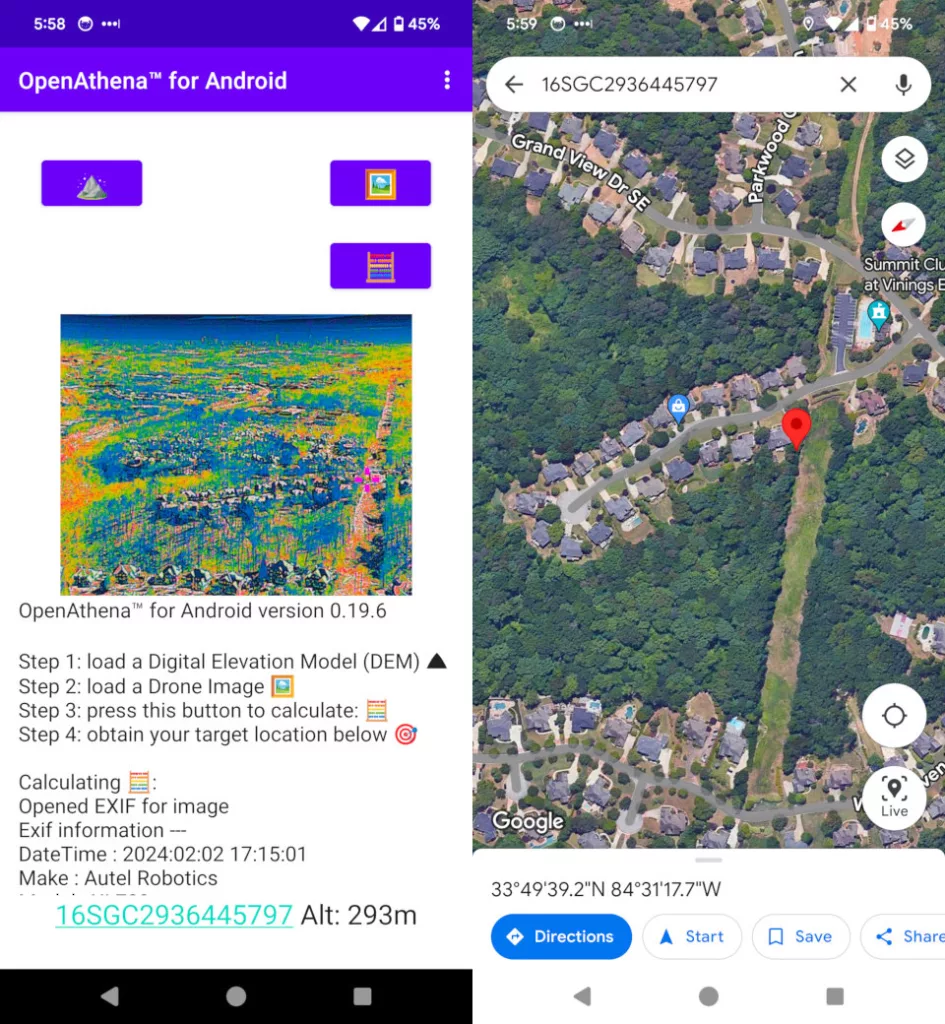
Demonstration of a location calculation from OpenAthena on
an image taken by a drone thermal camera. Device: Autel Evo II Dual 640T V3
For the software operator, the benefits of this technique manifest in a system which is faster and more accurate to use for obtaining actionable location information from drone imagery. These benefits are crucial for time-critical applications such as search and rescue, law enforcement, and defense, where speed, simplicity, and accuracy can mean the difference between a successful operation and an unsuccessful one.
Role of Artificial Intelligence:
At present, OpenAthena still requires a human operator to manually-identify and select an object of interest within drone imagery. This is perfectly adequate for processing imagery from a small area, but can pose significant difficulty when a human needs to review hundreds or thousands of images covering much larger areas. Humans need to be trained to recognize different classes of objects, they get bored, tired, can miss things, and require breaks and shift turnover for continuous operations. Additionally, each human reviewer operating near the front lines of conflict requires their own significant logistical tail. AI object detection models like Naissance for ATR, by contrast, can process thousands of images very quickly and thoroughly, operating 24/7 while never getting tired, bored, or needing a break.
The adoption of object detection AI for ATR in military contexts is expected to drastically shorten each cycle of the Observe, Orient, Decide, and Act (OODA) loop identified by former Air Force Colonel John Boyd as critical to battlefield outcomes. Autonomous systems may perform the Observe and Orient tasks of this loop instantaneously, speeding up the portion of the cycle prior to humans’ own Decision and Action. The combatant who can complete each full cycle of this OODA loop faster than their adversary is expected to enjoy a ‘decision advantage’ whereby they may routinely disrupt and overwhelm the enemy before they have the opportunity to react.
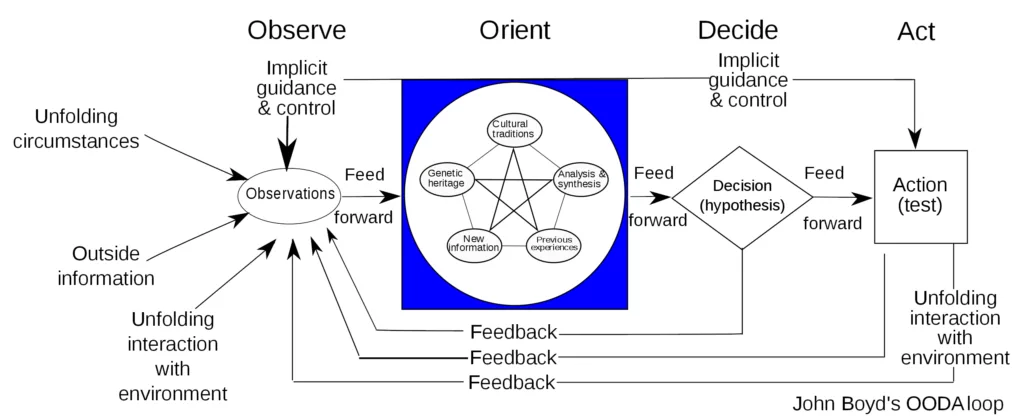
Graphic based on John Boyd’s original sketch in his 1995 presentation. ‘The Essence of Winning and Losing‘
Courtesy Patrick Edwin Moran, CC BY 3.0 DEED
Limitations of AI:
No matter how well they perform, such AI systems are not perfect. In rare cases, they can make mistakes (such as false positives or false negatives) of the kind that would never occur with a human analyst. In life or death situations, a human review is always needed due to the inherent unpredictability of such systems.

An unusual failure case in an early prototype of the Naissance object detection model.
Figure 3 (above) illustrates such a unusual and unpredictable failure case which was encountered early in the Naissance model’s development. The model routinely predicted that chicken coops were T-72 tanks with high confidence. Due to the model’s reliance on internal hidden layers for coming to a determination, it’s impossible to know why it came to it.
With the addition of more training data this behavior disappeared entirely, however its emergence in the first place is illustrative of the technical and ethical challenges of the use of AI for ATR. Deep learning techniques fundamentally are unable to provide the predictability and accountability needed for life or death decisions, especially compared to a human. They are much better suited however to the Observe and Orient tasks, helping humans to find the ‘needle in the haystack’ of copious data which can then be Decided and Acted upon.
Initial testing for project Naissance:
The original training and testing set for the Naissance model was a large dataset of synthetic computer graphics imagery. With such a sufficiently large dataset, the model achieved nearly perfect performance for detecting the desired object class:
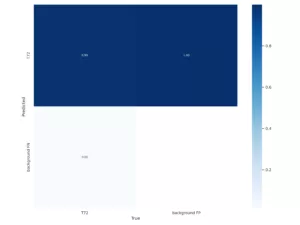

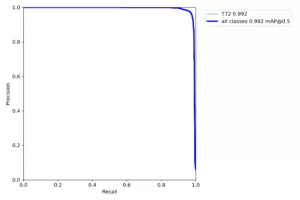
Figure 4
Test results from Naissance model on 932 labeled images never seen before by the model

Example of an excellent result from the Naissance Model
4x T-72 MBT’s are visible within an urban scene with a high degree of visual noise
The model is able to correctly identify all 4 objects with no false positives elsewhere
It is even able to identify a partially obscured object (center top) based on key identifying features
from just its rear section
Naissance robustness testing:
These tests were performed under ideal conditions. For the purpose of our research however, we desired to test how well this model would perform on complex real world scenes. The results however were much different than the above test:
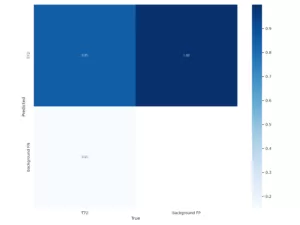
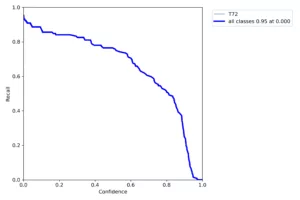
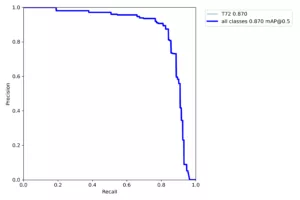
Figure 5
Test results from Naissance model on a labeled, real world dataset
The Confusion Matrix, Recall curve, and Precision/Recall Curve exhibit
significantly degraded performance compared to the previous test

Collage of bounding box predictions from Naissance model on real world images,
clearly exhibiting several errors. The top-left image shows the model failed to recognize an object instance
while the center-left image shows the model incorrectly identified an ambulance as a tank
The sub-optimal results of the previous test prompted our team to transition to an experimental, next-generation state of the art object detection AI model architecture.
Renaissance AI
Compared with previous architecture generations, this architecture contains an auxiliary branch which significantly reduces the distortion of visual information provided to the objective function throughout the model.
With this new architecture, our observation has been that its performance is drastically improved in multiple categories:
- The model learns much more quickly. Loss function convergence occurs much sooner in the training process, achieving the same level of mean Average Precision (mAP) within fewer training epochs.
- Significantly reduced rate of false positives, especially in complex scenes
- Significantly improved rate of recall, even in difficult and noisy scenes
Given these significantly improved results, we named this new model ‘Renaissance’. This name reflects its status as a rebirth of the original concept for project Naissance.
The test results and examples of the models significant capabilities are provided below:
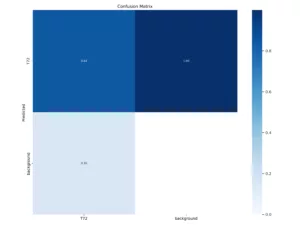
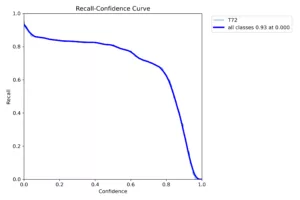
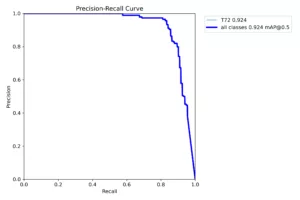
Figure 5
Test results from new ‘Renaissance’ model on a labeled, real world dataset
The new Recall curve and Precision/Recall Curve exhibit
significantly improved performance compared to previous architectures




Notably, the Renaissance AI model demonstrates significant ability to recognize the target object class even when its key identifying features are heavily obscured. This property is advantageous compared to simpler algorithmic approaches traditionally used for ATR:


















Video Demo:
Performance on Edge Hardware:
In a test on 242 real world images never before seen by the model during training or validation, the model achieved a precision statistic of 94.1% (meaning for every 100 detections only 5.9 were false positives) and a recall statistic of 82.6% (meaning for every 100 tanks within imagery, only 17.4 were missed). Mean Average Precision (mAP) core at 0.5 intersection over union threshold was 0.919:

Renaissance is a lightweight, ‘narrow AI’ object detection model designed to run inference at full motion video framerate onboard sUAS. While training the model requires high performance computing hardware, once trained it can be deployed on much less capable devices (such as NVIDIA and other NPU processors increasingly being included onboard drones).
The Renaissance Convolutional Neural Net is composed of roughly 25 million weight and bias parameters. This is many orders of magnitude smaller than multi-modal, generative AI models such as used in ChatGPT, which by comparison are unsuitable for running on edge computing hardware. For example, OpenAI’s GPT-4 is believed to consist of around 1.8 trillion parameters, requiring many hundreds of GPUs within large datacenters for inference. The Renaissance weights file is only 100 Megabytes, plenty small enough to fit onboard a drone.
Renaissance requires only about 100 Billion FLoating Point Operations Per Second (100 GFLOPS) of processing power throughput for live inference. This is well within the capability of modern drone hardware. The NVIDIA Jetson Orin, included on the Skydio X10D for example, is capable of 20 Trillion FLoating Point Operations Per Second (20 TFLOPS), a factor of 200x greater.
Methodology:
The Naissance and Renaissance projects are based on variants of the YOLO object detection framework. Proprietary techniques were developed by our firm for the curation, labeling, and transformation of data as well as the training process itself.
Just as in the Naissance project, the training data for project Renaissance was labeled and curated by hand over a significant quantity of hours of labor. We developed a procedure to issue secure computer hardware to U.S. based independent contractors for assistance in data labeling.
For model training, we transitioned away from the use of two NVIDIA RTX 4070 12Gb GPU’s on a Linux Workstation. Instead we designed and built a dedicated High Performance Computing (HPC) server named “ZEUS”, based on entirely consumer-grade PC Hardware:





ZEUS HPC parts list:
| Component | Model Name |
| Motherboard | MSI PRO B550-VC |
| GPU(s) | 4x Zotac (NVIDIA) GeForce RTX 3090 24GB Trinity OC |
| CPU | AMD Ryzen 5 5500 6 Core 3.6 GHz |
| RAM | 128 Gb G-Skill Ripjaws V DDR4-3200 |
| SSD | Samsung 980 Pro NVMe |
| PSU | Seasonic Prime TX-1600 | 1600W | 80+ Titanium |
| Case | Kingwin KC-6GPU-SS open air miner case |
| PCIe extenders | 4x Asiahorse 200mm PCIe 3.0 x16 shielded extender |
Performance:
142 Trillion Floating Point Operations Per Second (TFLOPS) at 16-bit precision
Tuning:
Traditional performance tuning operations on the Linux operating system improved general stability and performance. To prevent the computer from drawing too much electricity and tripping an electrical breaker, we adapted a script from the following article which limits the power usage of the NVIDIA GPUs (with only modest performance impact):
https://gist.github.com/mkrupczak3/2c7f17d7730b11c981b7feab48e76d4c
Compared to the use of cloud hardware rental or NVIDIA’s datacenter hardware solutions, the use of consumer hardware allows us to operate at significantly lower marginal cost for the production of each AI model. This approach significantly improves the rate at which we can iterate for production of new AI models.
Conclusion:
The pace of emerging technology in aerial robotics, data processing techniques, and AI is rapidly precipitating changes in land warfare doctrine. Our firm, Theta Informatics LLC, aims to be the nexus of progress of such technology in order to ensure free societies are better equipped and prepared for it than autocratic adversary nations. Autocracies’ inflexible thinking, poor tolerance of diverse groups and ideas, and rigid protocols will prevent them from adopting such technology as efficiently as free societies. Doctrinal evolution is necessary to preserve the rules-based international order established by free societies since the end of WWII in the face of historic challenges this century.
At the time of writing, Theta Informatics LLC is a pre-seed startup specializing in software and intellectual property holdings. We are actively looking for strategic partners including UAS manufacturers, system integrators, software contributors, investors, and end users in service of our firm’s mission.
We can be reached at the following email: inquiries@theta.limited
To see more from Theta, sign up for our newsletter and follow our official X (formerly Twitter), YouTube, and LinkedIn pages.
Edits:
2024-12-12 Add additional images and new performance section